Working Papers
My working papers are divided into two areas:
- Field experiments aimed at improving prioritization, primarily in K-12 education
- Investigations of the adoption, perception, and impact of common prioritization methods in social service bureaucracies, with comparisons between manually-defined points systems, lotteries, beneficiary requests, and predictive models/algorithms
Area one: field experiments
Revise and resubmit
- Wilson, Johnson (equal first authorship), Hatzimasoura, Holman, Moore, and Yokum. Evaluating the Effects of Nurse-Led Triage of 911 Calls: A Randomized Controlled Trial. Revise and Resubmit at Nature Medicine
Abstract: Each year, millions of Americans call 911 for time-sensitive issues that don’t require Emergency Medical Services (EMS). In need of medical help, these callers may treat 911 as an entry point into the healthcare system, yet an ambulance to the emergency department can harm both their own long-term health and the health of others. In a field experiment in Washington, DC, ($n = 6,053$ callers) we find that placing nurses directly into its 911 call center in order to triage low-acuity calls reduced unnecessary ambulance transports by 39%. For Medicaid callers, it more than tripled primary care visits within 24 hours of their 911 call and reduced unnecessary emergency department visits by 14.9%. While other 911 reforms have denied callers access to alternative resources, our findings show the value of reforming 911 by offering appropriate care rather than denying resources.
To be submitted
- Johnson, DiDomenico, Balu, Turner. Navigating to Opportunity? A Randomized Controlled Trial of Placing College Navigators in Public Housing
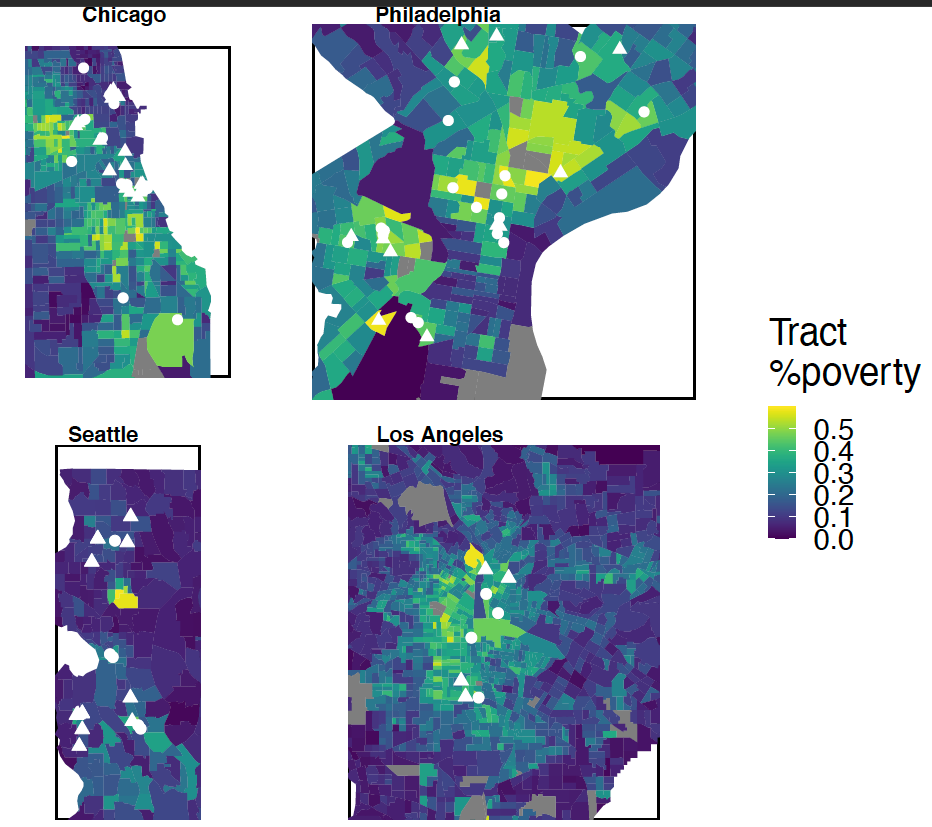
Abstract: There are persistent socioeconomic and racial disparities in U.S. postsecondary enrollment. Yet there remains a gap between the modal type of intervention—``nudge-type’’ interventions that leave a teenager’s neighborhood and school context unaltered—and rarer interventions that alter this context by either promoting mobility out of them or investing mentorship resources into them. Past studies of whether mentors help either lack racial diversity or prioritize “efficiency’’ over equity, offering mentors to students identified as promising candidates rather than anyone who might need one. The present study helps address gaps between theories of gaps and interventions to reduce them. We present the first results from a field experiment (Project SOAR) where the U.S. Department of Housing and Urban Development (HUD) provided over $2 million to nine public housing authorities (PHAs) to hire “education navigators,” physically located at the housing site, to help resident teenagers apply for financial aid and attend college, residents eligible by age rather than college promise. In an experimental analysis with four PHAs in SOAR where we randomized access to college navigators (N = 3,834 residents; 96% Black or Hispanic/Latino; median household income ~$17,000), we find no statistically significant impact of access to navigators on postsecondary outcomes, results confirmed in a quasi-experimental synthetic control analysis of the five remaining PHAs. Finally, we use a mix of two data sources—qualitative site visit data; computational text analysis of detailed logs that navigators kept on their interactions with residents—to explore mechanisms for why the intervention did not produce hoped for impacts on stratification.
- Johnson and Mei. Technology and Educational Triage: Evidence from Large-Scale Messaging Data
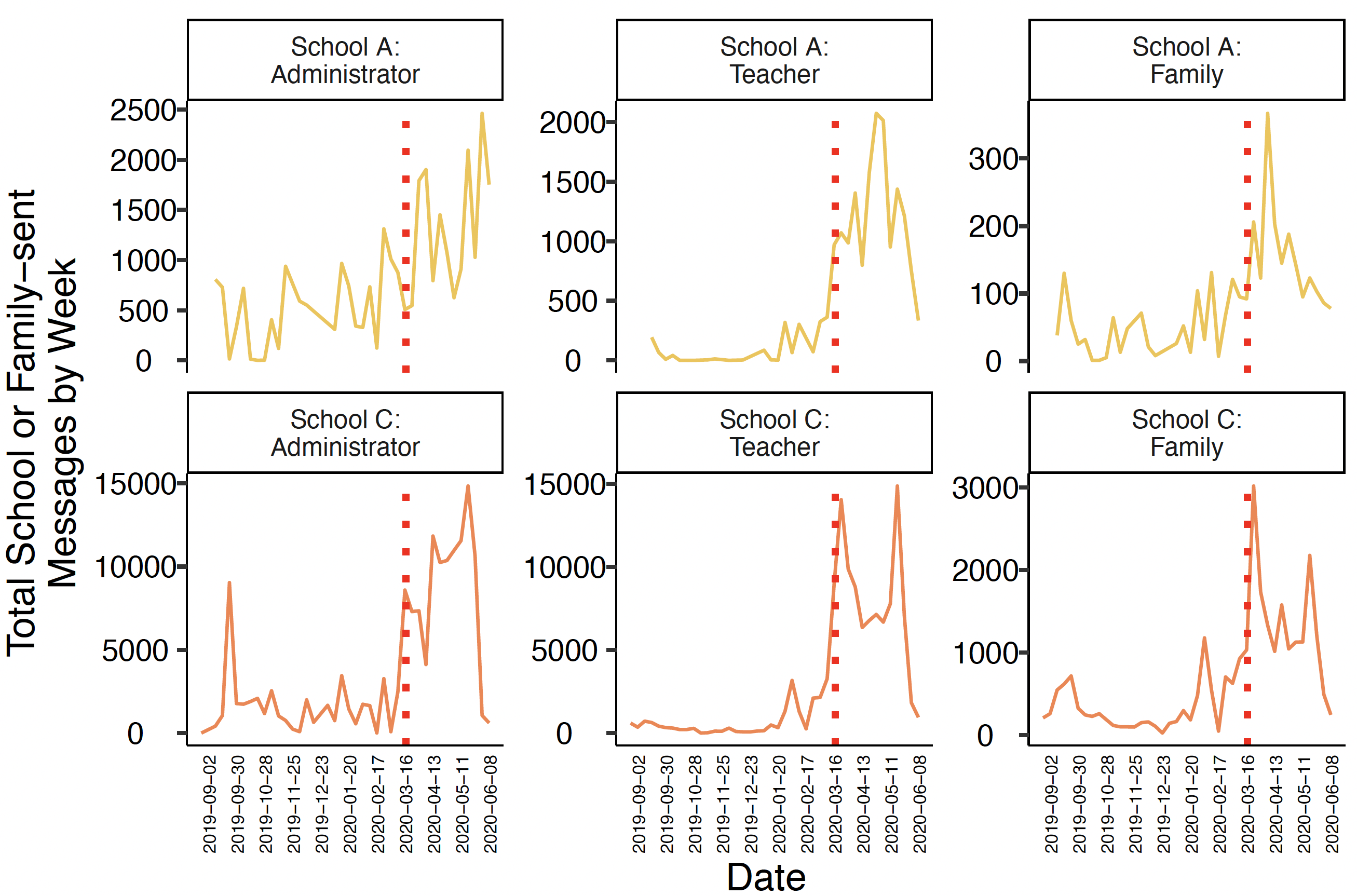
Abstract for text analysis: A large body of research documents inequalities in family-school interactions. Yet the methodologies used—either intensive ethnographic observation of families and teachers or survey-based measures that ask families to self-report their school involvement—create gaps in our understanding of how family-school interactions impact inequality. These gaps became more apparent during COVID-19, as policy concerns emerged about families “disappearing’’ from contact during virtual learning confronted methods ill-suited to measure these changes. The present project draws upon a randomized controlled trial of “TeacherText”, a web and mobile-based application that makes it easier for teachers and school administrators to interact with families (e.g., auto-translations; training on positive messages). We use large-scale metadata and messaging data from the platform (~340,000 messages between 208 school staff and 4,298 parent-student dyads; 6 DC Public and Public Charter schools; messaging in 2019-2020 before and during COVID-19 online pivots), linked to administrative data from the district’s student information system (SIS), to investigate two questions about family-school interactions during virtual pivots. First, we show that when examining interactions longitudinally, disappearance from contact is much rarer than two other statuses: interactions both before and after the COVID-19 virtual pivot (modal status) or no interactions either period. Then, we use text analysis to highlight two mechanisms for how school staff continued to engage families: the use of tools to simultaneously interact with many families and the platform expanding beyond academic-focused messages to messages connecting families with social services. Concluding, we discuss the benefits and challenges of using “digital trace data” to measure family-school interactions.
- Johnson. Simko, and Imai. Bridging Gaps? A Randomized Controlled Trial of A Summer Bridge Program for First-Generation/Low-Income Students
- Cooper, DiDomenico, and Johnson (equal authorship). Using Supervised Machine Learning to Predict Nonresponse and Target Incentives
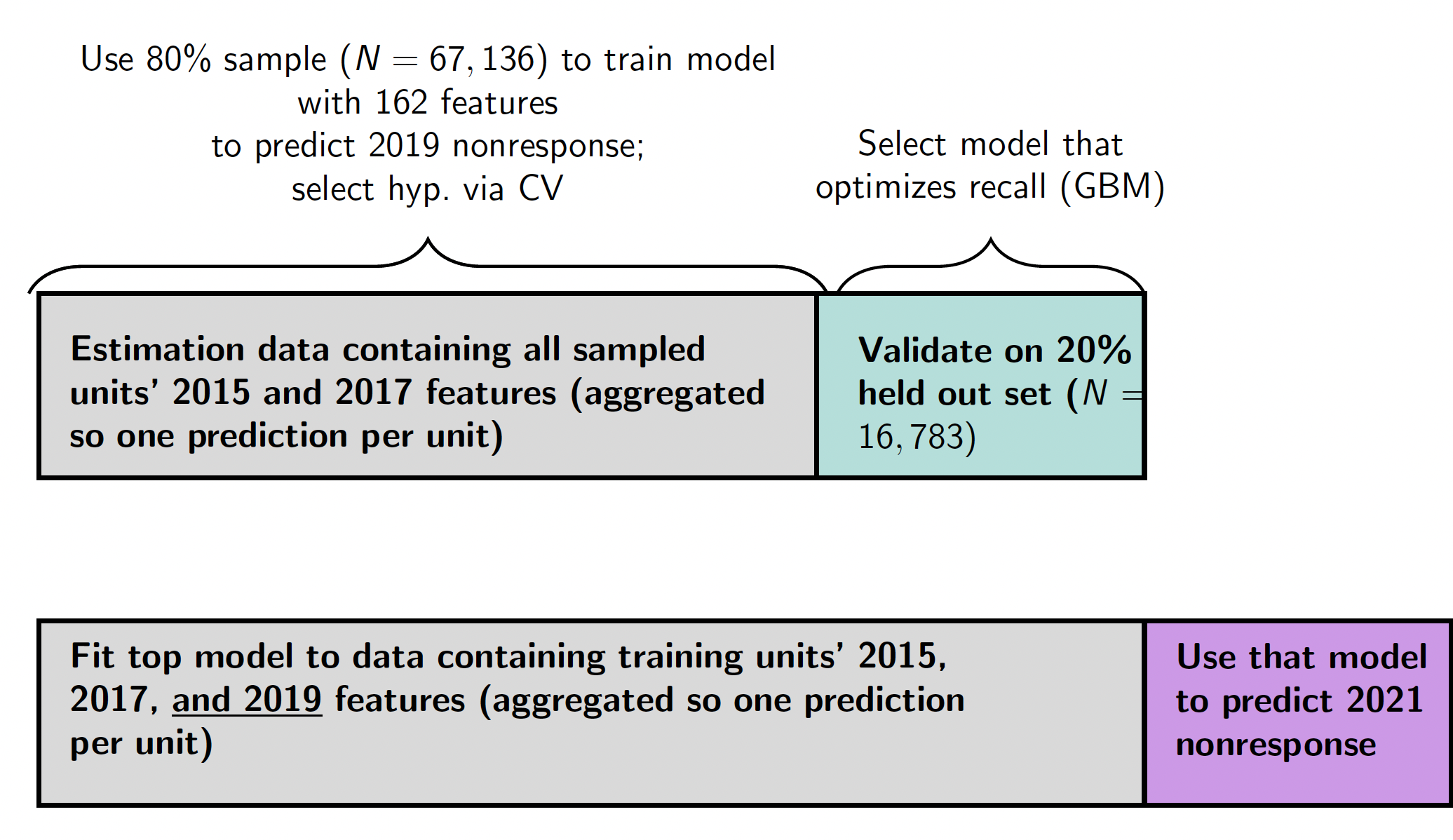
Abstract: Demographic surveys are experiencing declining response rates that can contribute to nonresponse bias. The present working paper argues that new tools from supervised machine learning (SML) can improve efforts to mitigate that bias. We use the case of the American Housing Survey (AHS), a longitudinal survey developed by HUD and administered by Census Bureau, to show this application. First, we outline a model where survey planners with a finite quantity of resources (e.g., time; financial incentives) to prompt response can either target these resources based on a unit’s nonresponse risk or randomly allocate these resources. Then, we outline a two-part field experiment designed to test the impact of risk-based targeting on nonresponse bias. In Section 4—nonresponse prediction—we draw on large-scale data—internal files from the AHS that contain information on both responders and nonresponders; contact history data; contextual data—to show that we can use supervised machine learning (SML) to predict nonresponse with a relatively high degree of accuracy. We argue though that, in the case of longitudinal surveys, there may also be gains in switching from random targeting to a more parsimonious ``rule-based’’ method that looks at a focal respondent’s response history. Then, in Section 5—evaluating the impact of prediction-based targeting on survey bias—we outline pre-registered analyses for a field experiment with the 2021 wave of the AHS, with results expected Spring 2022. Concluding, we discuss the generalizability of our findings to other cases of risk-based targeting.
Area two: prioritization in social service bureaucracies
To be submitted
- Johnson. Rationing via Categorical Discretion: Unequal Monitoring of School Decisions and Stratification
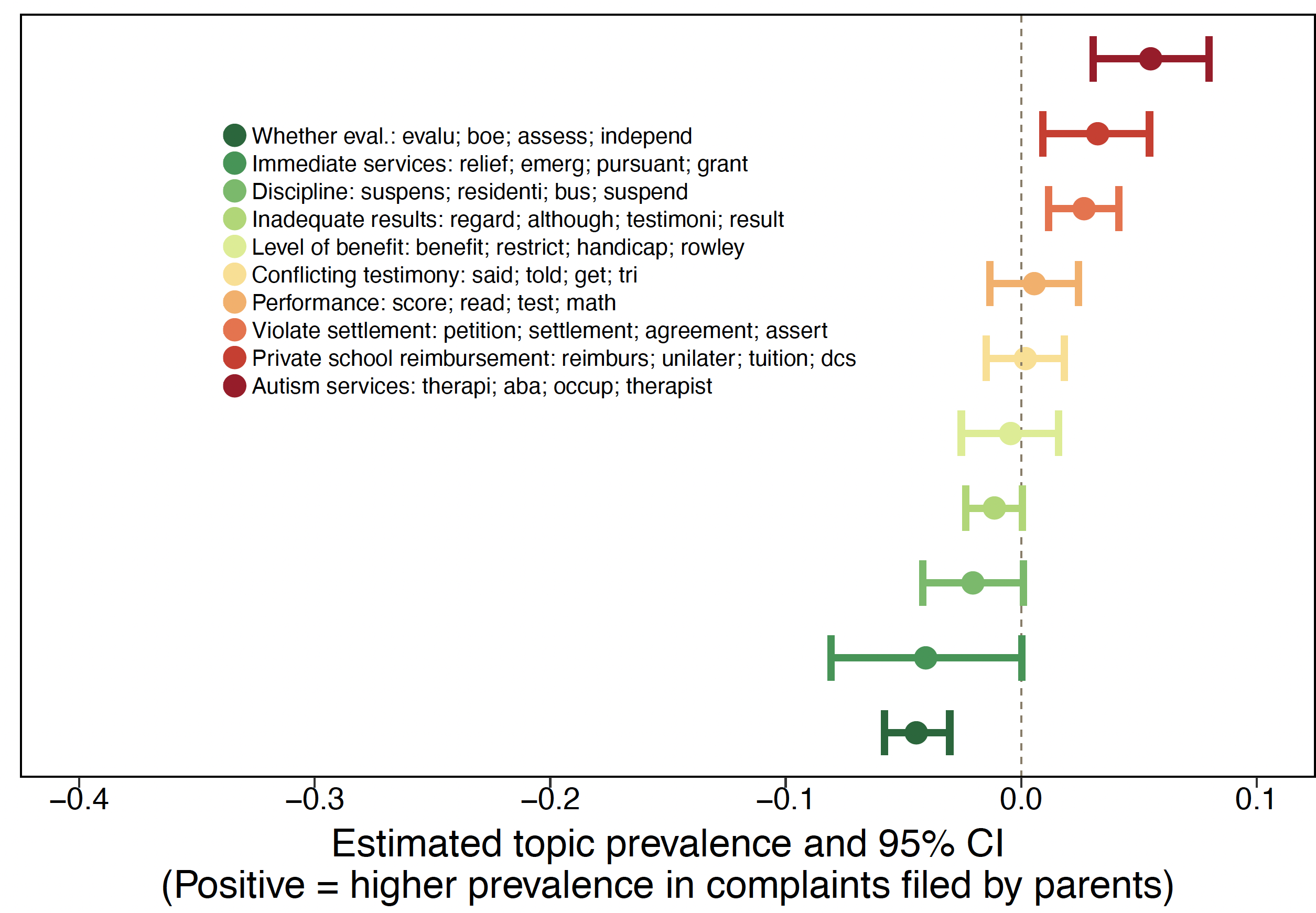
Abstract: This project investigates how school districts grapple with ethical dilemmas about whom to help as they navigate legal mandates that conflict with fiscal realities: state and federal requirements for districts to prioritize certain categories of students coupled with prohibitions on allowing cost to influence decisions.
My research shows that these mandates do not eliminate rationing. Rather, they encourage rationing by inconvenience; hidden roadblocks to receiving extra help that deter all but the most persistent parents and advocates. This yields two forms of unequal access to justice. The first is between different categories of students: parents of students with disabilities have rights to insist that the student receives more resources, while parents of students in other categories like students living in poverty or struggling to learn English have weaker rights. The second form of inequality is within the disability category. While all parents have the same formal rights, there is unequal rights enforcement. The project uses spatial analyses of due process filings and computational text analyses of hearing decisions to illuminate these patterns of inequality. By studying this case, the project aims to contribute to research on the role of civil enforcement in anti-poverty policy and on how to use tools from computational social science to study everyday forms of legal adversity.
- American Bar Foundation/JPB Foundation Access to Justice Scholarship
- Working Paper
- Conference Presentation on Categories and Spillover Effects
- Conference Presentation on Unequal Discretion to Ration
- Johnson, Kappes, Hall, Zhang, Williams, Bell. Local Discretion Addresses Competing Allocation Goals: The Case of Small Business Relief Funding

Abstract: Organizations responsible for distributing limited resources, such as government agencies and non-profit organizations, face conflicts over how to select and evaluate recipients, with political feasibility constraints often at odds with equity goals. Previous research has left unanswered the question of how organizations evaluate which other organizations deserve resources and the impact of their selection procedures on inequality. These issues were salient as local economic development organizations allocated COVID-19 relief to U.S. small businesses. We leverage observations, simulations, and quantitative and qualitative survey responses to better understand how local discretion affects the share of resources that go to small businesses owned by women, racial and ethnic minorities, and individuals with low incomes. Qualitative coding of local selection procedures (Study 1) showed that local organizations varied in terms of who they defined as the beneficiary of relief—small business organizations versus owners—and the criteria they used to prioritize recipients—based on the business’ merit versus their need. To test how the variation in selection procedures affected access to help, we used real application data from businesses in three cities (Study 2). Simulations showed that when selection procedures used economic criteria to give higher priority to “meritorious” businesses, women- and minority-owned businesses were placed at a disadvantage. However, selection procedures that give a demographic plus factor to these businesses corrects for these inequalities. Finally, we used a vignette-based experiment to understand whether members of the public perceive these inequalities as fair (Study 3). Together, these studies show how and why local discretion to prioritize meritorious organizations for relief can contribute to racial, ethnic, and gender disparities in access to resources.